Written by Andrei Dmitrenko and Philipp Warmer
In recent years, Generative AI (GenAI) has taken center stage, especially with the advent of Large Language Models (LLMs). These models promise to transform knowledge work, and they seem to be living up to expectations. The latest LLMs are nearing human-level performance on several benchmarks (Street et al. 2024). For more details, see Street et al., 2024. This progress has caught the attention of corporations, which are now integrating LLMs into their workflows to boost productivity and efficiency in business processes.
One prominent way to integrate GenAI into business processes is by building applications around generic foundational LLMs. The prime spot is currently taken by so-called Retrieval Augmented Generation (RAG) applications. In essence, RAG enhances the AI's capabilities by providing the LLM with relevant chunks of private knowledge, selected based on semantic similarity, during the generation process. This way, the application provides more accurate and contextually relevant outputs without the need to train a model to incorporate new pieces of information.
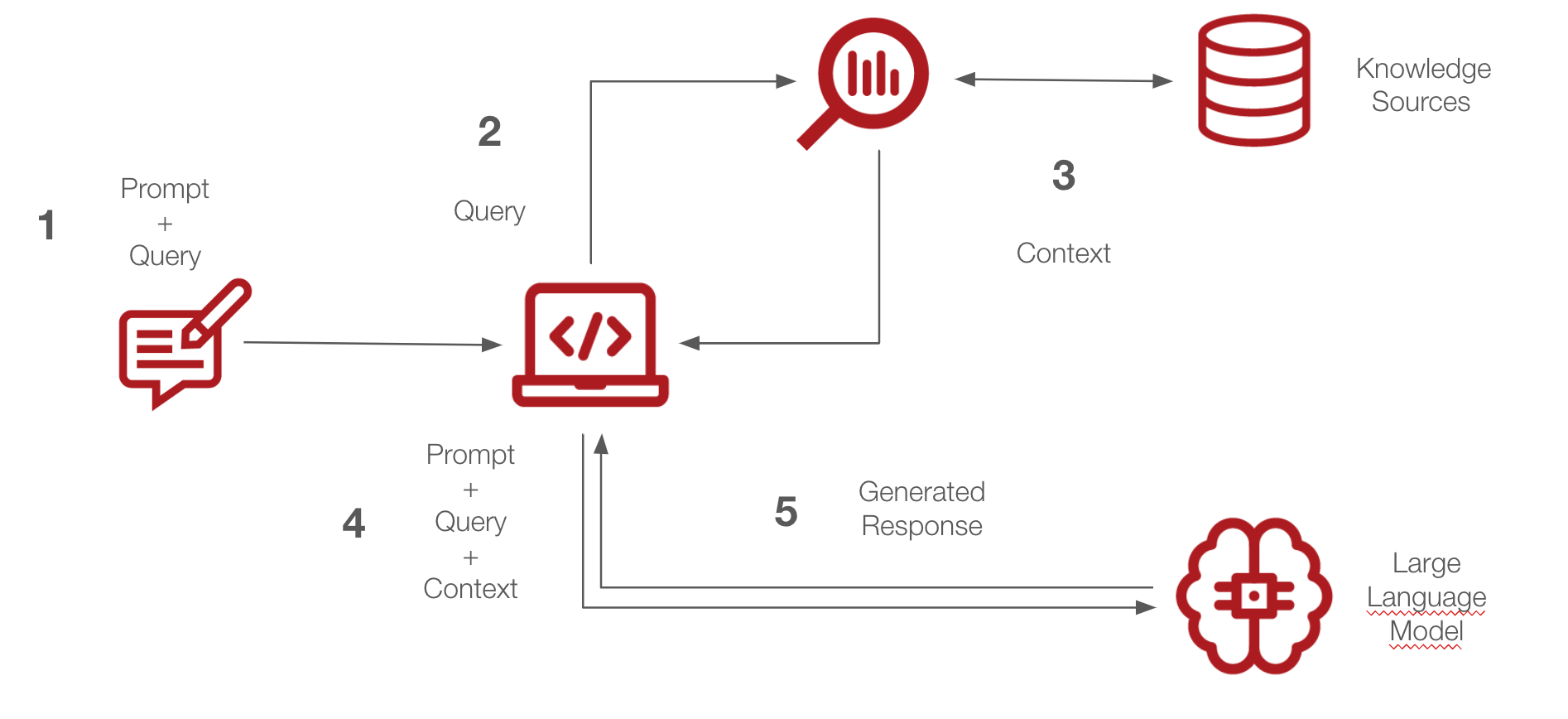
Customizing LLM applications depends heavily on understanding the unique needs and constraints of the corresponding industry or business domain. For instance, a healthcare application prioritizing patient data privacy might have stringent security protocols, whereas a customer service bot could value quick response times and high availability more.
We conducted a survey among professionals building such applications in alignment with business stakeholders. Our primary goal was to understand the expectations and pain points of business professionals when dealing with LLM-based solutions. We asked participants to assign an importance to the following features for a GenAI app in their current business domains, using a scale from 1 to 5:
Instead of a broad survey, we targeted data professionals at D ONE who worked on GenAI projects closely interacting with business stakeholders in 2024. This focused approach ensured we obtained relevant insights from recent projects in legal-tech, reinsurance, manufacturing customer support, service marketplace, and consulting.
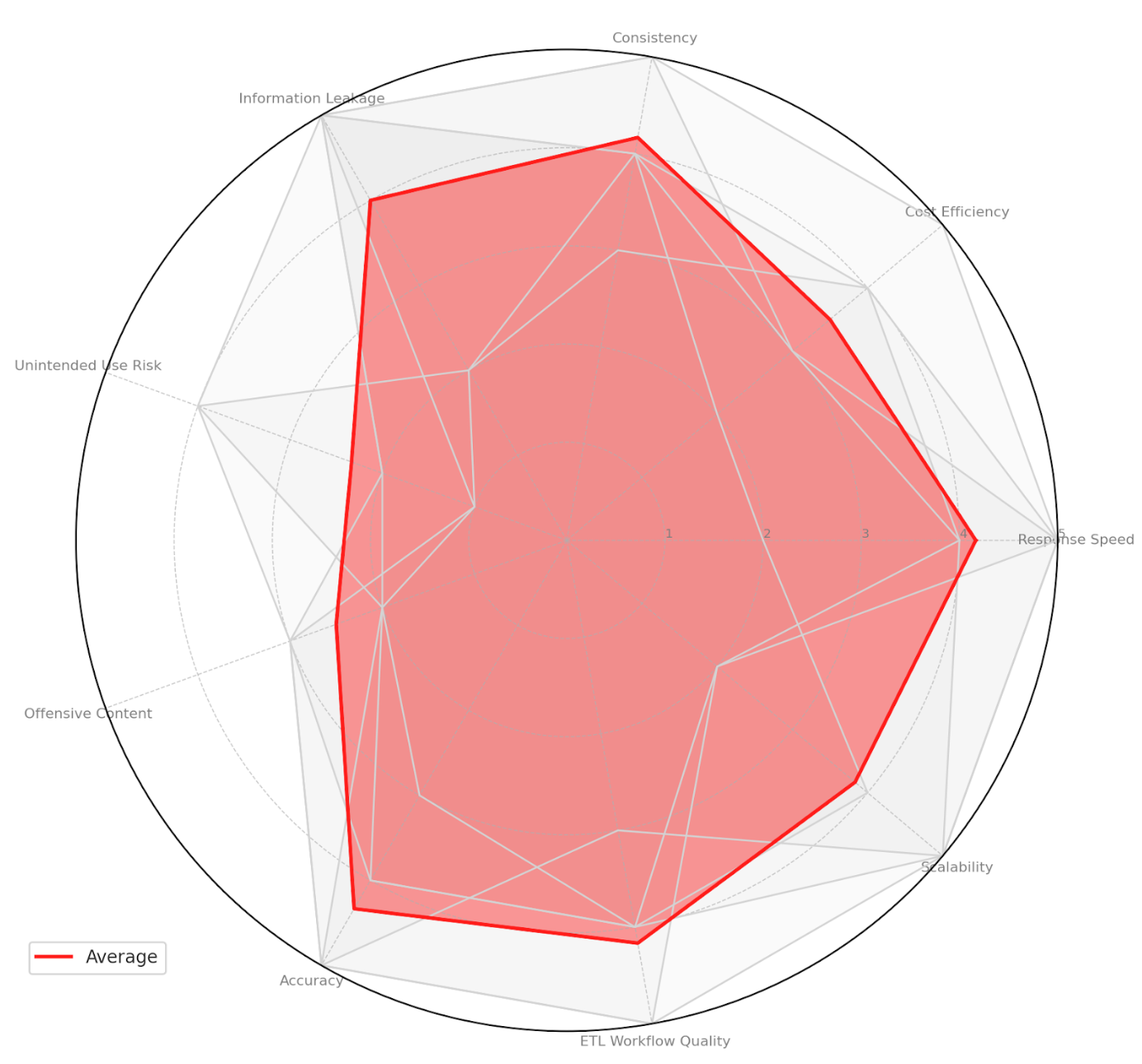
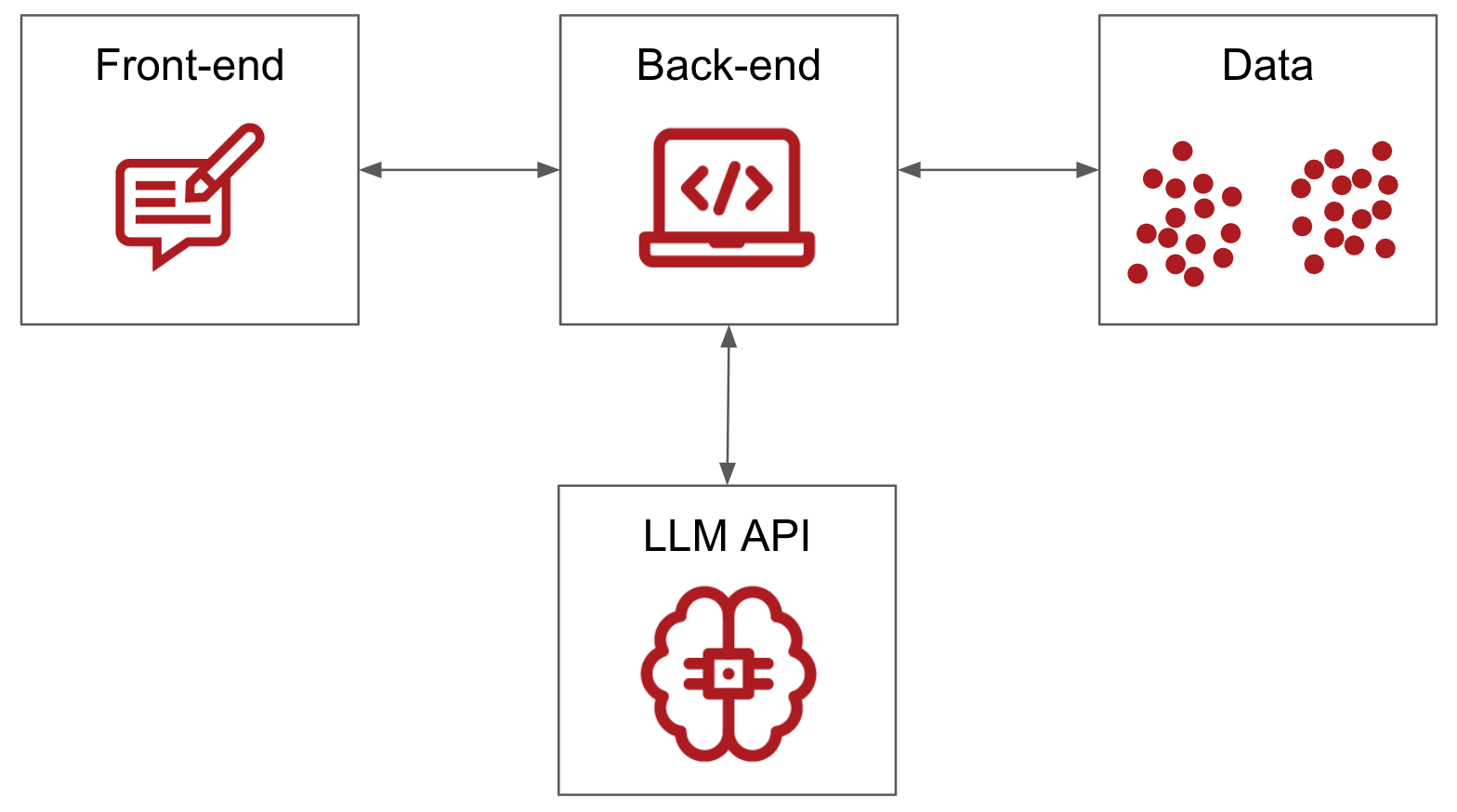
Now that we have hands-on experience building such apps in various business domains and analyzed the end-user perspectives, we can emphasize the above key insights and map them onto the respective parts of the RAG architecture.
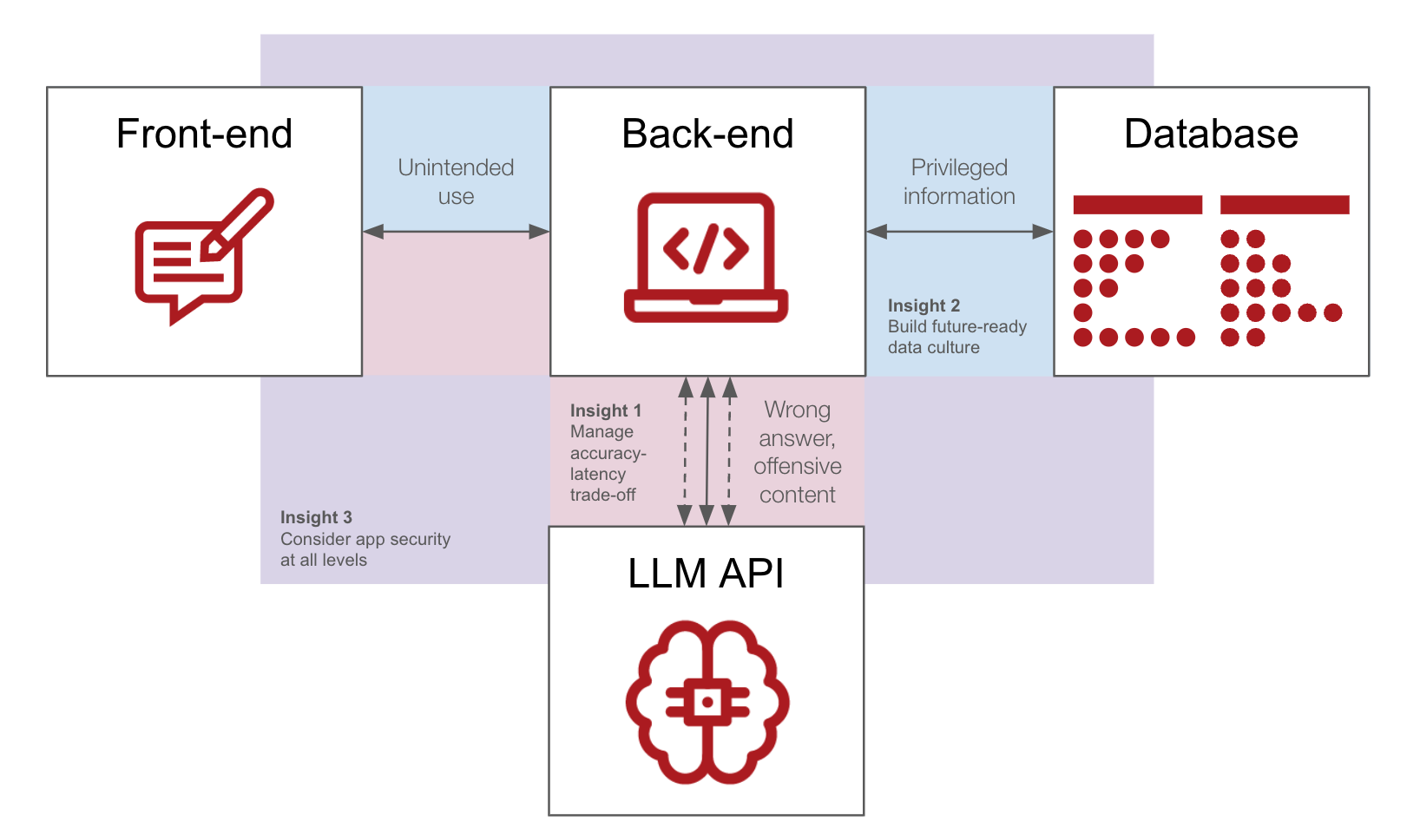
From our observations as a Data & AI consultancy firm, RAG is a widespread solution that effectively addresses business needs across industry sectors and continues to improve. If RAG is here to stay, it certainly requires a systematic view of its architecture, highlighting critical components and potential vulnerabilities.
Looking forward, we anticipate a new level of complexity in building RAG apps introduced by multimodality, involving simultaneous processing of textual, imaging, audio, and video data. This emphasizes the importance of secure architectures to address potential vulnerabilities. At D ONE, we are quickly accumulating practical knowledge on developing and deploying GenAI apps, and brainstorming solutions even before new challenges emerge.
Looking for a companion on your journey towards a data-driven enterprise leveraging the most recent AI technologies? Reach out to us.