Named Entity Recognition (NER) is a fundamental NLP task that involves extracting specific entities such as organizations, people, dates, and more, from unstructured text. While this process is effective in detecting sets of entity groups, it often strips away the broader context and relation between the extracted entities. However, advancements in Large Language Models (LLMs) offer a solution to this limitation.
LLMs, with their advanced text understanding capabilities, can make the extraction process more intelligent by mapping entities to a predefined schema. This way they can maintain the intricate word relation and context, transforming how we approach NER. Here’s a breakdown of this process:
We start by establishing the specific conditional relation we want to explore. This is a shift from traditional NER methods that indiscriminately extract all entities of a certain type. For example, if we’re interested in how a drug affects a receptor in the context of a disease, we would define the relation as follows:
A affects B in condition C ⇒ Relation(A->B | C)
Once the conditional relation is set, we generate a few examples to guide the LLM. This step helps the model understand the specific structure of the information we’re seeking.
Drug affects Receptor in Disease ⇒ Relation(Drug->Receptor | Disease)
.. now here is the place to get very specific with expected relations
There are several approaches to using LLMs for structured information extraction:
To better understand how these components integrate, let’s first visualize the approach in a simple schema and let’s apply it using the OpenAI API with GPT-4.

Figure 1: We feed into the LLM prompt: (1) the expected conditional relation, (2) the few-shot examples and the text containing the unstructured relation (3).
Let's get specific and have a look at a code snippet that can be used to extract relations using GPT-4 and functions.
import os
from dotenv import load_dotenv
import json
import openai
# Let's load in the openai api key
load_dotenv()
openai.api_key = os.environ["OPENAI_API_KEY"]
# In this function we define the relation and extract it using GPT-4
def extract_relation(prompt: str):
"""
Function for conditional relation extraction using OpenAI API
Args:
prompt (str): Text containing the relation
systemsmessage (str): Message to guide the extraction process or provide context.
Returns:
str: The extracted relation as a response message, formatted in the context of
Relation(A->B | C).
"""
# Basic setup: Here we define systemsmessage and prompt of interest
messages = [{"role": "user", "content": prompt}]
# This is where the magic happens, here we describe the relation we want to extract and give examples
functions = [{
"name": "conditional_relation_extraction",
"description": """
Extract from scientific literature the following conditional relation: A affects B in the condition C ⇒ Relation(A->B | C)
Examples:
Drug affects receptor in cancer
Chemotherapy affects DNA replication in tumor cells.
Trastuzumab attaches to HER2/neu in breast cancer.
Adalimumab targets TNF-alpha in rheumatoid arthritis.
""",
"parameters": {
"type": "object",
"properties": {
"a": {
"type": "string",
"description": " in Relation(A->B | C) return A - often a drug, effector or tool.",
},
"b": {
"type": "string",
"description": " in Relation(A->B | C) return B - often a drug target, protein or subject.",
},
"c": {
"type": "string",
"description": " in Relation(A->B | C) return C - often a disease or condition.",
},
}
},
"required": ["a", "b", "c"],
}]
# We plug in the messages and function in the OpenAI API
response = openai.ChatCompletion.create(
model="gpt-4",
messages=messages,
functions=functions,
function_call={"name": "conditional_relation_extraction"},
)
response_message = response["choices"][0]["message"]
return response_message
Voila that's already the setup — now we simply call the function to extract the relations!
# Dummy example how this function is called.
abstracts = ["[Placeholder scientific literature 1]", "[Placeholder scientific literature 2]", "[Placeholder scientific literature n]"]
relations = [extract_relation(abstract) for abstract in abstracts]
For a given abstract, the extract_relation function has extracted the relation A affects B in
the condition C ⇒ Relation(A -> B | C). For clarification, a dummy example can be seen below.
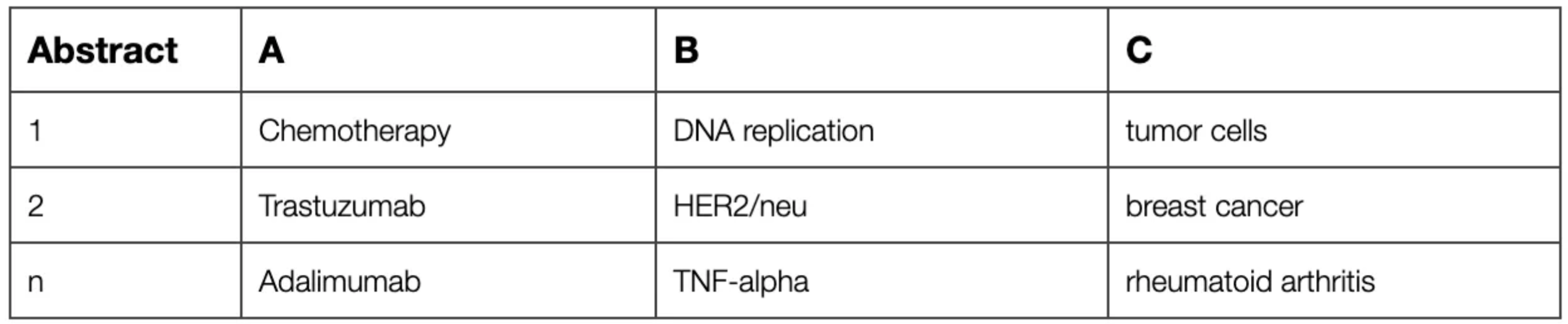
We have seen how to set up a conditional relation and implement it in Python using GPT-4 with the OpenAI API. Now let's have a look at a couple of conditional relation examples that the code, just as the one above, could extract.
Enough with theory, let’s crystallize how we can use this approach by observing use cases from different domains:
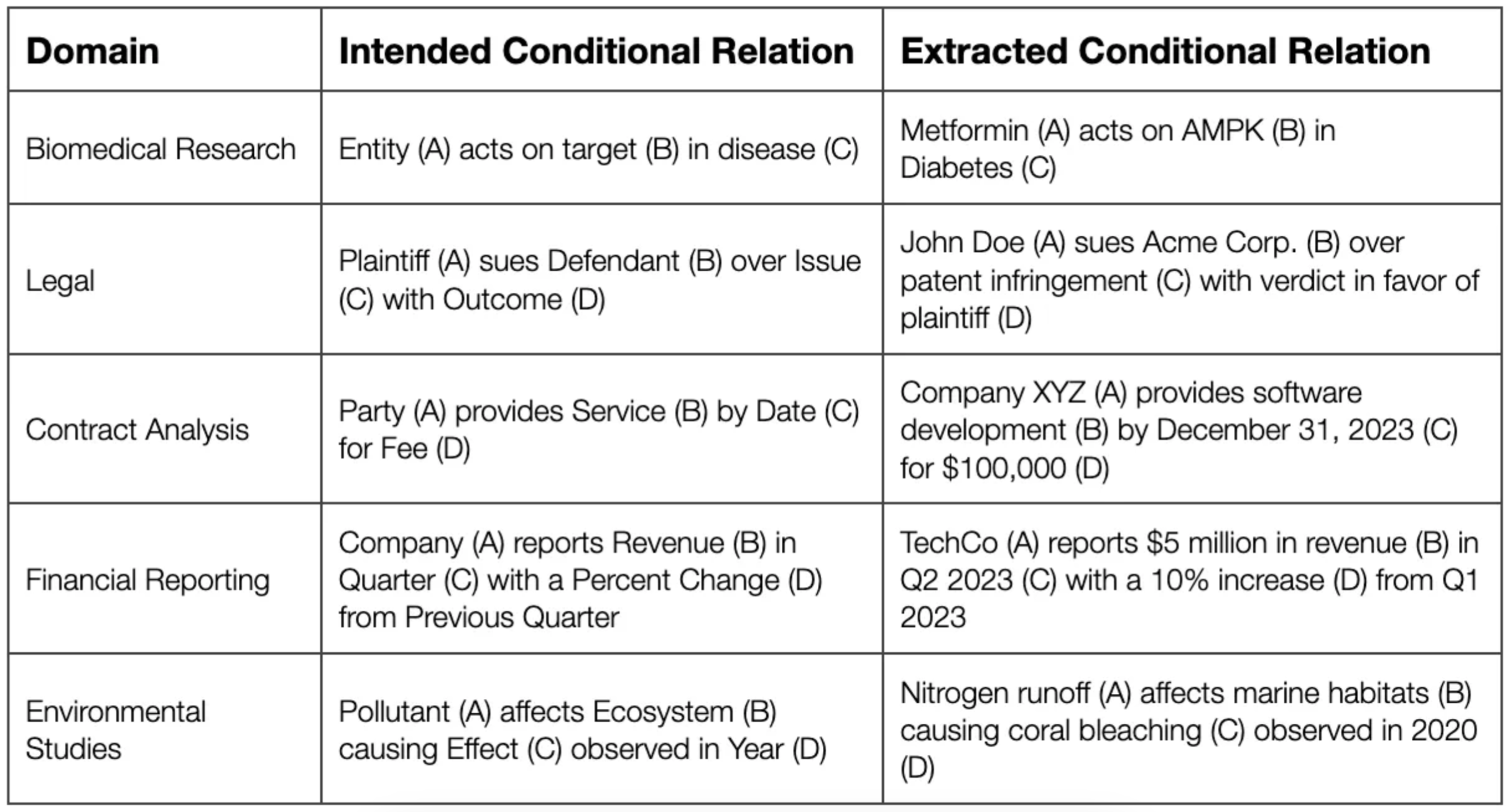
Table with examples from different domains how applied conditional relation extraction can look like.
These are some a handful of examples to underline that using this approach, plenty of use cases are just waiting to be tackled. Feeling inspired?
While extracting conditional relations from small texts is straightforward, larger documents or cross-document analysis pose challenges:
Extracting from large documents can be challenging due to the limited context window size of LLMs:
Solution: Implement intention-aware document summarization. By chunking and summarizing with an intent to preserve the desired relation, we maintain essential information while managing document size. Once reduced in size, we can supply the document into the prompt. If still too large, why not redo this exercise till it fits?
Solution: Normalize components using shared ontologies or numerical transformations (like BERT embeddings or n-grams). This helps in constructing a global relation graph based on the entities' similarity.
Conditional relation extraction is a step towards activating unstructured data and making it comprehensible for both humans and machines. Using a form of hyper summarization is a new way to interact with and understand large volumes of data.
Having a fun application in mind or just want to chat, get in touch via LinkedIn.